
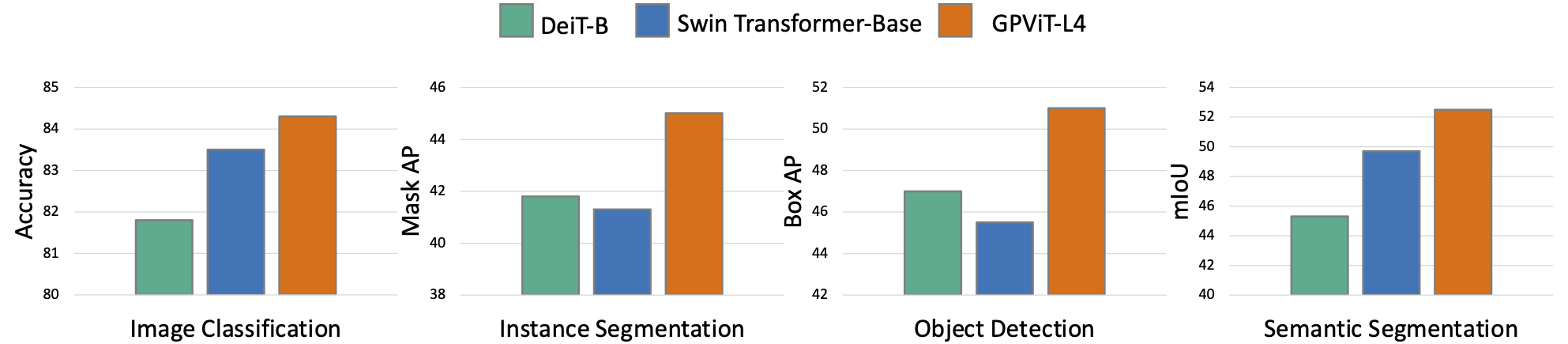
We present the Group Propagation Vision Transformer (GPViT): a novel non-hierarchical (i.e. non-pyramidal) transformer model designed for general visual recognition with high-resolution features. High-resolution features (or tokens) are a natural fit for tasks that involve perceiving fine-grained details such as detection and segmentation, but exchanging global information between these features is expensive in memory and computation because of the way self-attention scales. We provide a highly efficient alternative Group Propagation Block (GP Block) to exchange global information. In each GP Block, features are first grouped together by a fixed number of learnable group tokens; we then perform Group Propagation where global information is exchanged between the grouped features; finally, global information in the updated grouped features is returned back to the image features through a transformer decoder. We evaluate GPViT on a variety of visual recognition tasks including image classification, semantic segmentation, object detection, and instance segmentation. Our method achieves significant performance gains over previous works across all tasks, especially on tasks that require high-resolution outputs, for example, our GPViT-L3 outperforms Swin Transformer-B by 2.0 mIoU on ADE20K semantic segmentation with only half as many parameters.

We achieves high-resolution non-hierarchical vision transformer by combining local attention blocks and our GP Blocks,
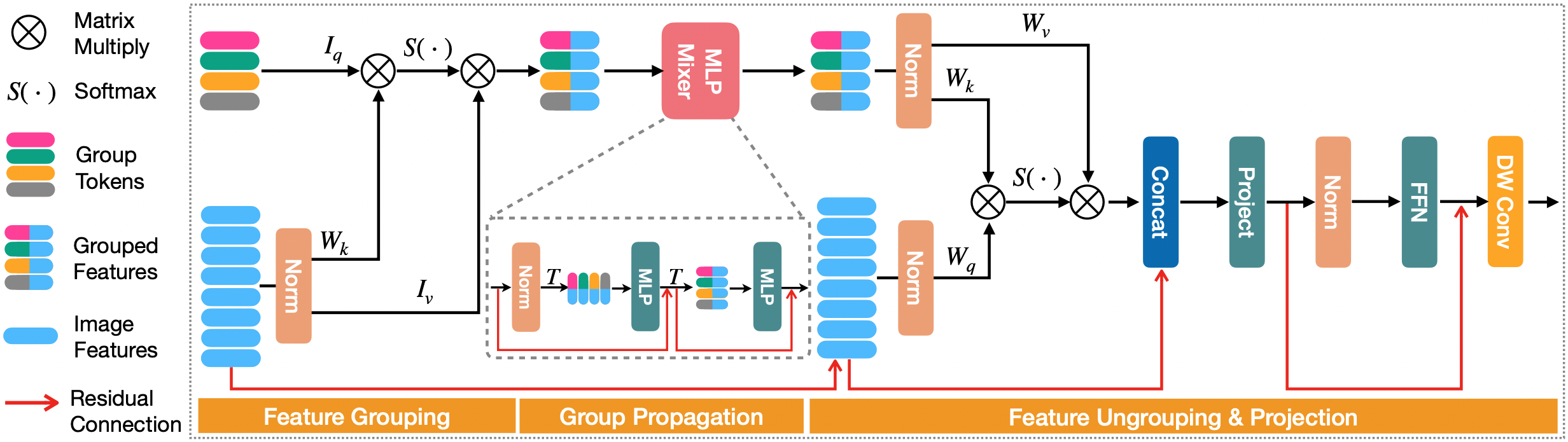
Our Group Propagation Block (GP Block) achieves efficient global information exchange on high-resolution features. It has three stages: Feature Grouping: The high-resolution image features are grouped by a set of learnable group tokens with cross-attention operation; Group Propagation: Global information are exchanged in the grouped features with a MLPMixer block; Feature Ungrouping: The updated grouped features are queried by image features with cross-attention to transfer global information to every image feature.



























































@inproceedings{
yang2023gpvit,
title={{GPViT: A High Resolution Non-Hierarchical Vision Transformer with Group Propagation}},
author={Chenhongyi Yang and Jiarui Xu and Shalini De Mello and Elliot J. Crowley and Xiaolong Wang},
booktitle={International Conference on Learning Representations},
year={2023},
url={https://openreview.net/forum?id=IowKt5rYWsK}
}