Chenhongyi Yang
杨陈弘毅
About Me
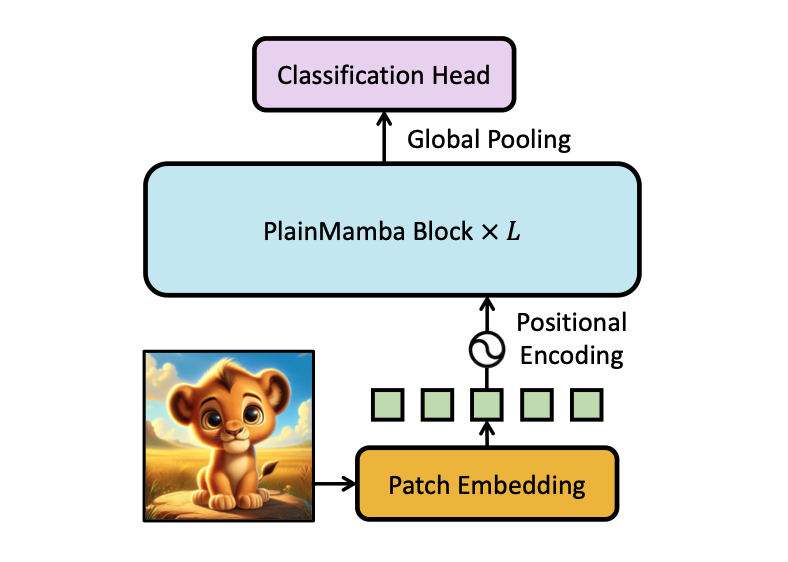
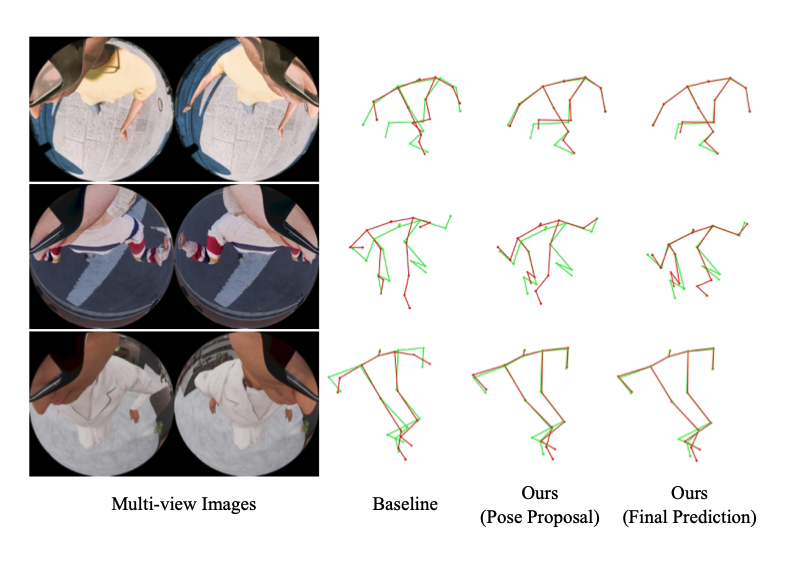
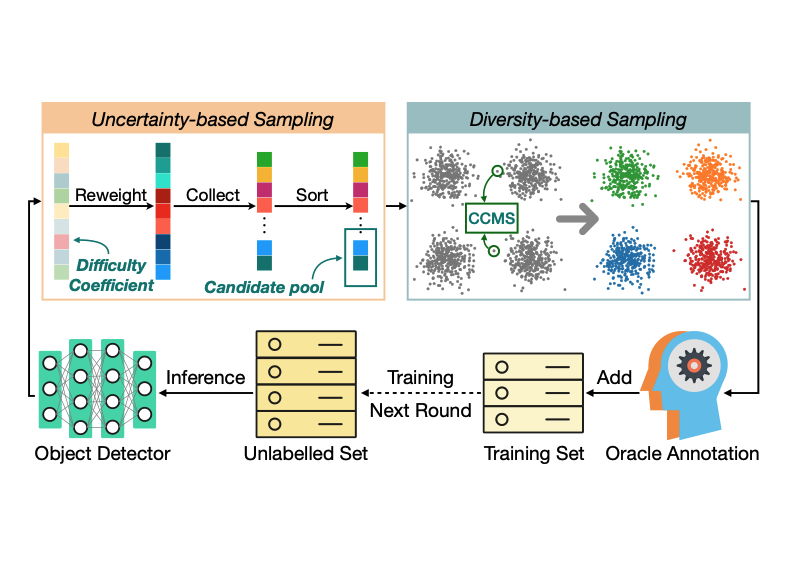
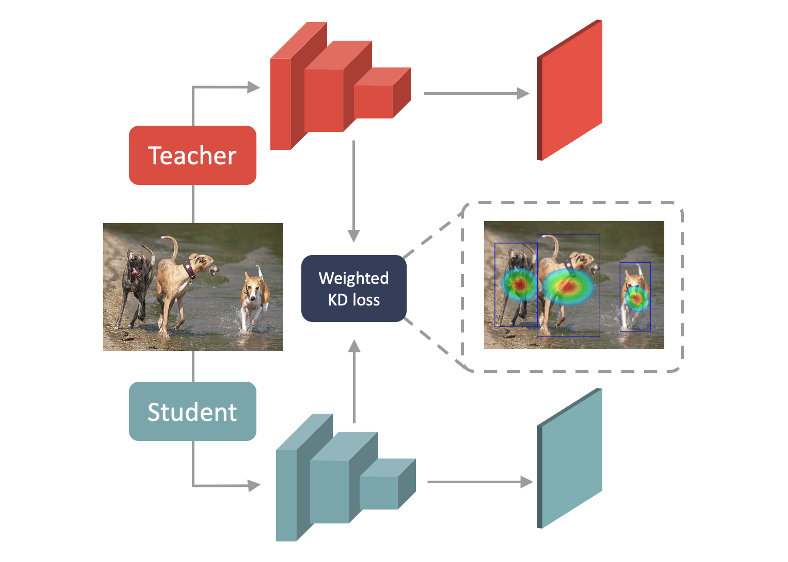
I am a research scientist at Meta Reality Labs, working on human body modelling. Before joining Meta, I got my PhD from the University of Edinburgh, under the supervison of Dr Elliot J. Crowley. My PhD research was in computer vision, with a focus on developing effective neural networks for 2D and 3D visual perception and designing efficient training algorithms for visual recognition models. I hold an MSc in computer science from Boston University and BEng in computer science from the University of Science and Technology of China.
Selected Publications
-
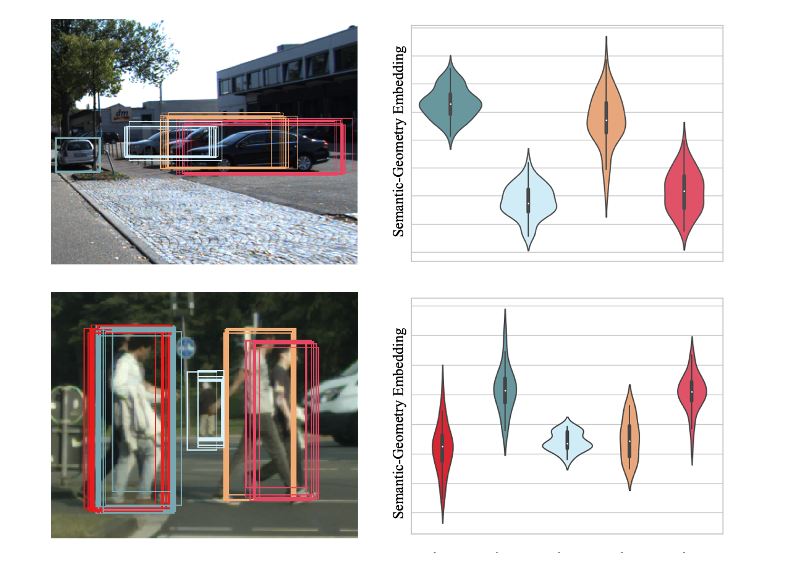
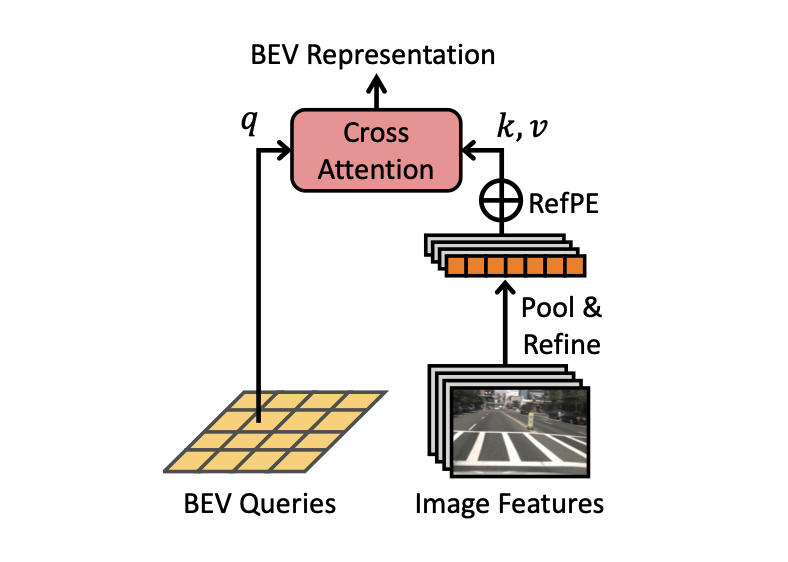 IROS 2024
IROS 2024 -
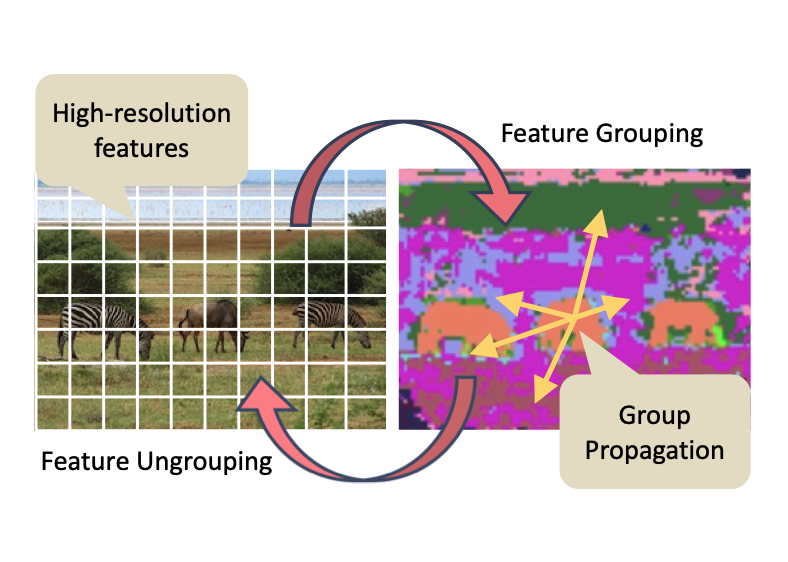 ICLR 2023
ICLR 2023 -
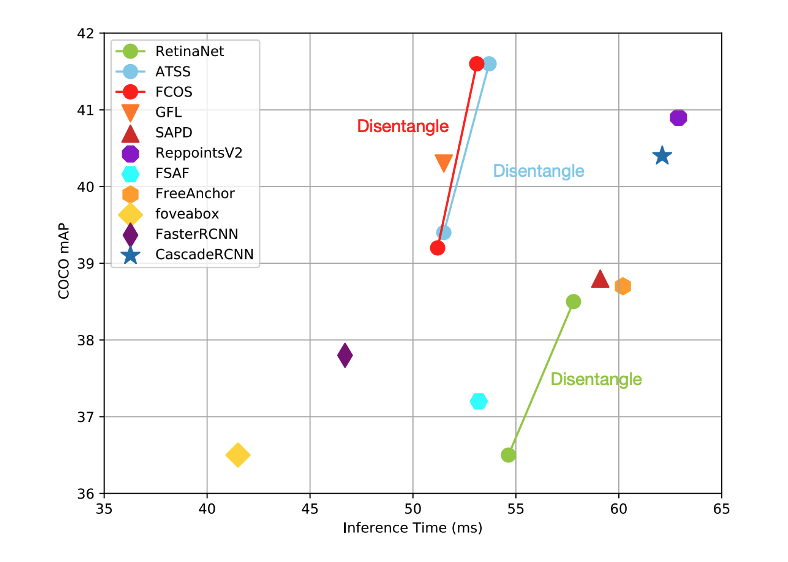
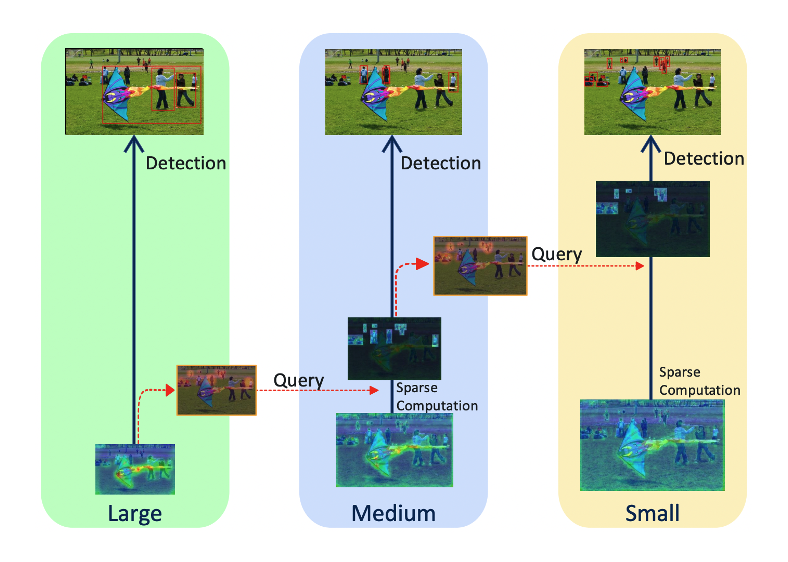 CVPR 2022
CVPR 2022 -
Powered by Jekyll and Minimal Light theme.