




I am currently a final-year PhD student working on computer vision problems at the School of Engineering, University of Edinburgh, under the supervision of Dr. Elliot J. Crowley. I am part of the BayesWatch group. Previously, I earned my MSc degree in computer science at Boston University, supervised by Prof. Margrit Betke and Dr. Vitaly Ablavsky. Before that, I obtained my BEng degree in computer science from the University of Science and Technology of China.
During my PhD study, I interned at Meta Reality Labs, working with Dr. Anastasia Tkach. Prior to my PhD, I spent a year at TuSimple as a research intern, working with Dr. Naiyan Wang.
My PhD research focuses on two main areas: developing effective neural networks for 2D and 3D visual perception, and designing efficient training algorithms for visual recognition models. Currently, I am focusing on finding good strategies to adapt visual foundation models to various downstream vision tasks.
Latest Works
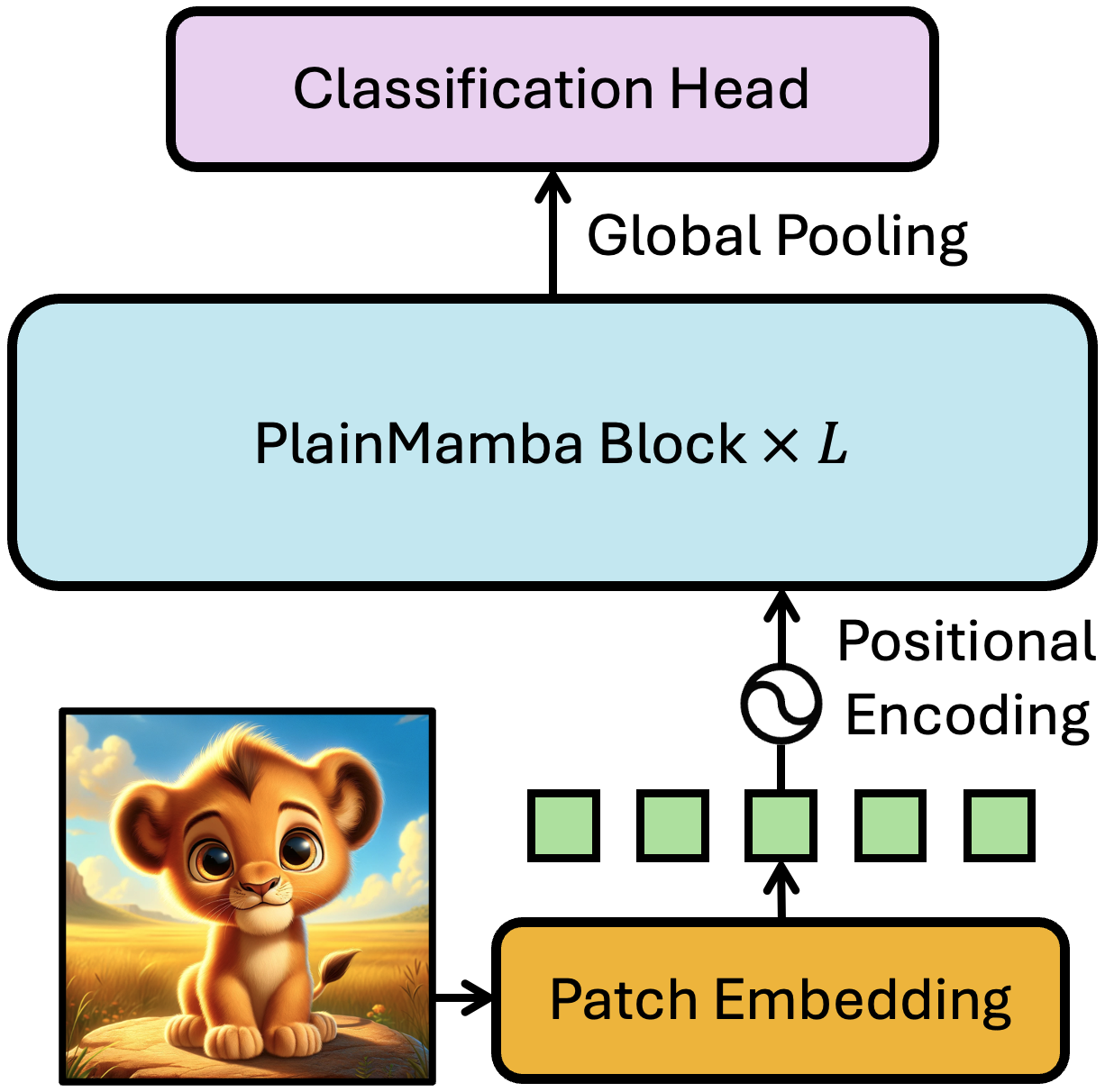
PlainMamba: Improving Non-Hierarchical Mamba in Visual Recognition
Preprint, 03/2024 
Chenhongyi Yang*, Zehui Chen*, Miguel Espinosa*, Linus Ericsson, Zhenyu Wang, Jiaming Liu, Elliot J. Crowley
PlainMamba is a non-hierarchical SSM designed for general visual recognition. It achieves better benchmark results than vision transformer with a linear computation complexity.
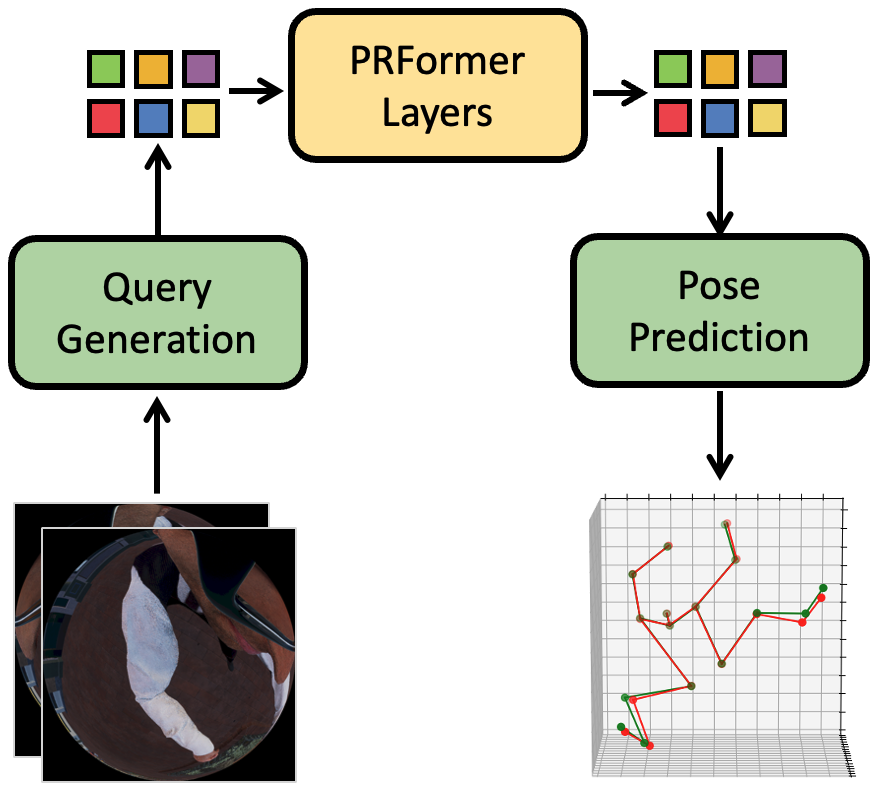
EgoPoseFormer: A Simple Baseline for Egocentric 3D Human Pose Estimation
Preprint, 03/2024
Chenhongyi Yang, Anastasia Tkach, Shreyas Hampali, Linguang Zhang, Elliot J. Crowley, Cem Keskin
EgoPoseFormer is a simple transformer-based model for egocentric 3d body pose estimation that can be used in both stereo and monocular settings. It significantly outperforms the previous state-of-the-art approaches with much less computation cost.
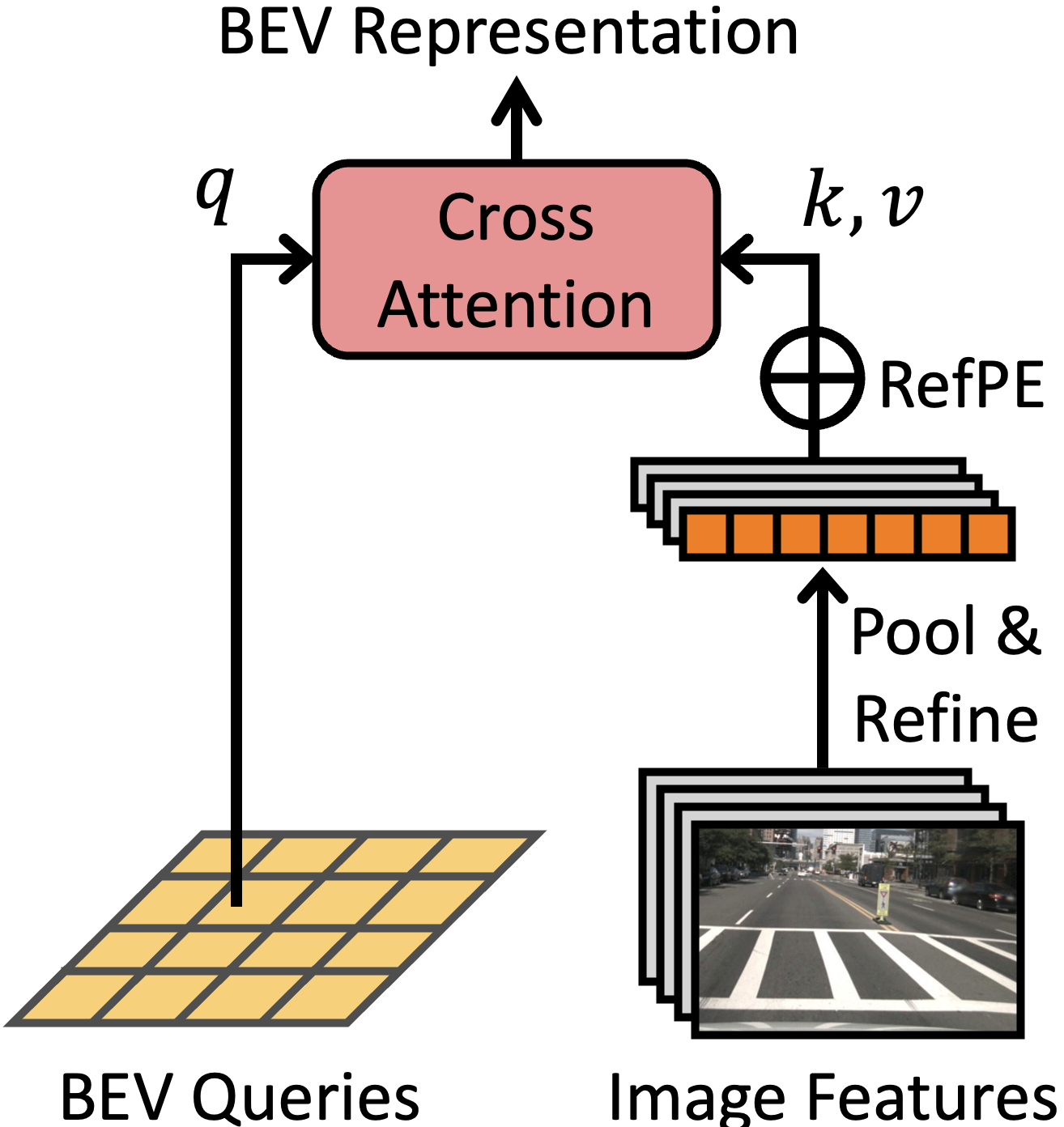
WidthFormer: Toward Efficient Transformer-based BEV View Transformation
Preprint, 01/2024
Chenhongyi Yang, Tianwei Lin, Lichao Huang, Elliot J. Crowley
WidthFormer is an efficient and robust transformer-based BEV transformation method. It is built upon a feature compression mechanism and an effective 3D positional encoding mechanism. Moreover, our new 3D positional encoding is also beneficial for sparse 3D object detectors.
PlainMamba: Improving Non-Hierarchical Mamba in Visual Recognition
Preprint, 03/2024
Chenhongyi Yang*, Zehui Chen*, Miguel Espinosa*, Linus Ericsson, Zhenyu Wang, Jiaming Liu, Elliot J. Crowley
PlainMamba is a non-hierarchical SSM designed for general visual recognition. It achieves better benchmark results than vision transformer with a linear computation complexity.
EgoPoseFormer: A Simple Baseline for Egocentric 3D Human Pose Estimation
Preprint, 03/2024
Chenhongyi Yang, Anastasia Tkach, Shreyas Hampali, Linguang Zhang, Elliot J. Crowley, Cem Keskin
EgoPoseFormer is a simple transformer-based model for egocentric 3d body pose estimation that can be used in both stereo and monocular settings. It significantly outperforms the previous state-of-the-art approaches with much less computation cost.
WidthFormer: Toward Efficient Transformer-based BEV View Transformation
Preprint, 01/2024
Chenhongyi Yang, Tianwei Lin, Lichao Huang, Elliot J. Crowley
WidthFormer is an efficient and robust transformer-based BEV transformation method. It is built upon a feature compression mechanism and an effective 3D positional encoding mechanism. Moreover, our new 3D positional encoding is also beneficial for sparse 3D object detectors.
Selected Publications
A full list of publication is on Google Scholar.
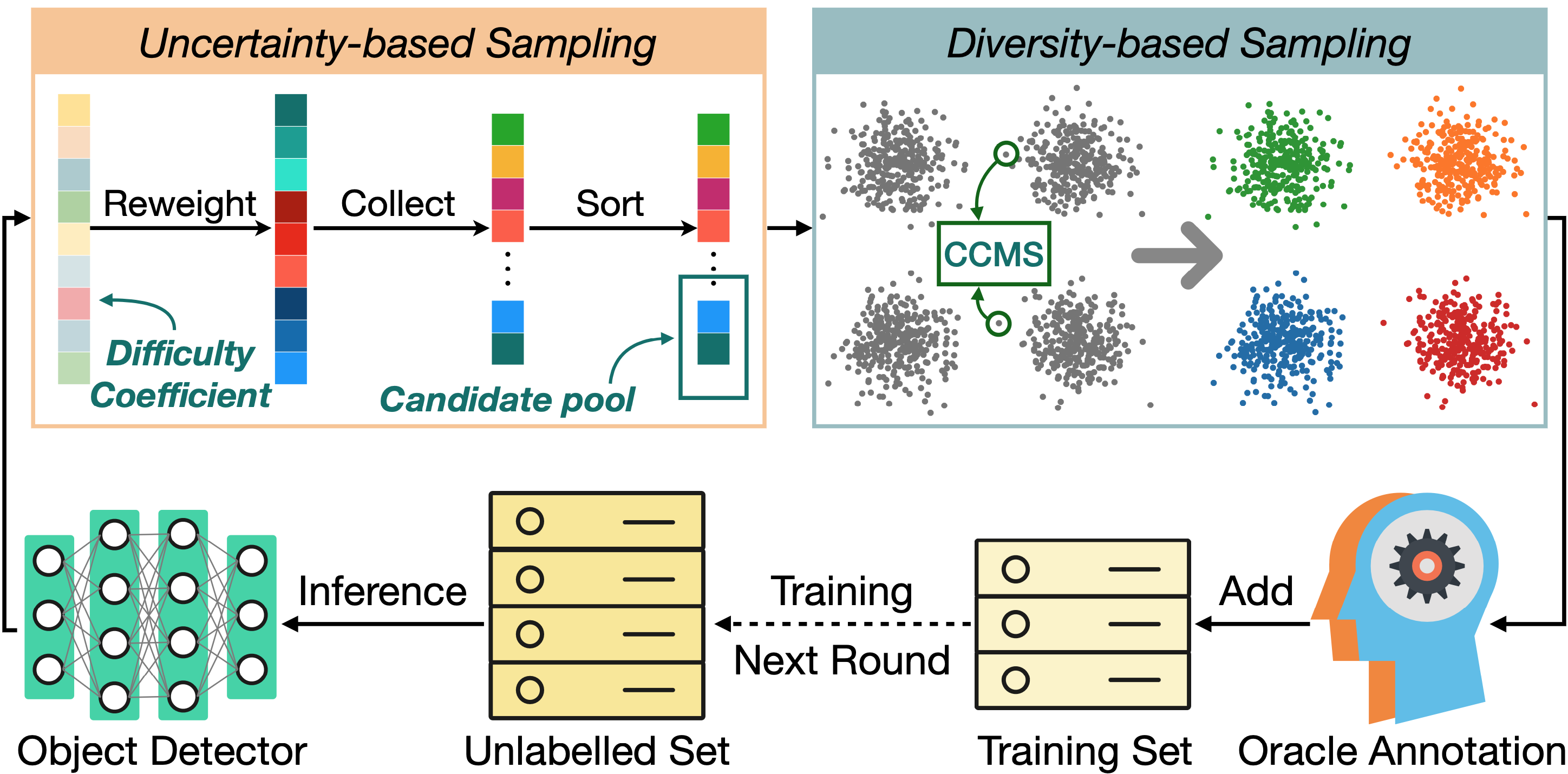
Plug and Play Active Learning for Object Detection
CVPR 2024
Chenhongyi Yang, Lichao Huang, Elliot J. Crowley
PPAL is a plug-and-play active learning framework for object detection. It is based on two innotations: a novel object-level uncertainty re-weighting mechanism and a new similarity computing method for designed multi-instance images.
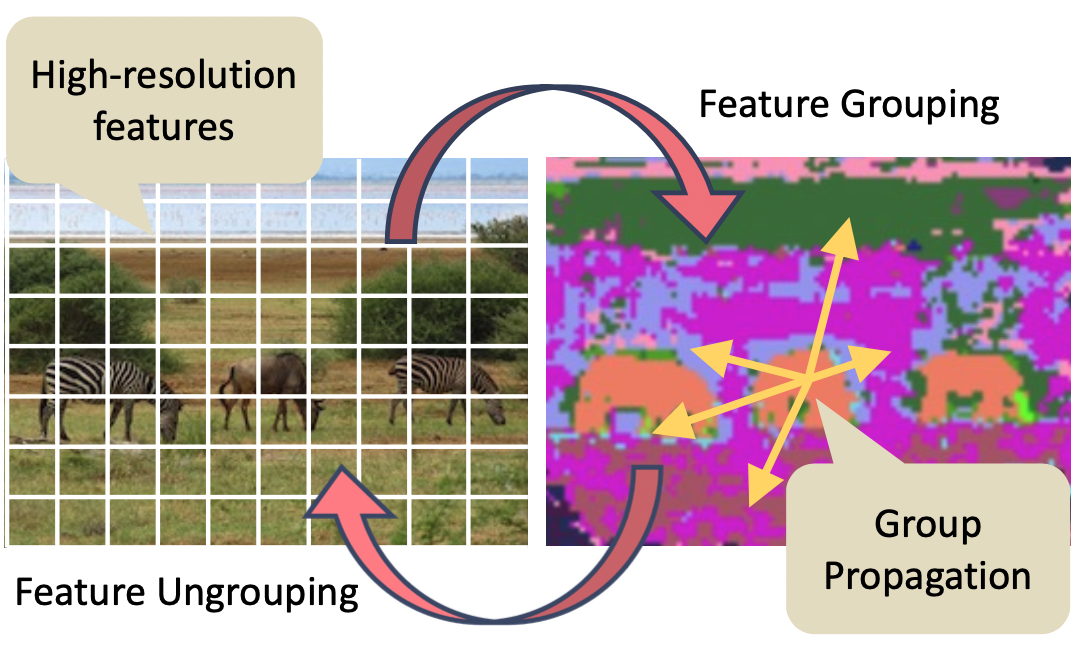
GPViT: A High Resolution Non-Hierarchical Vision Transformer with Group Propagation
ICLR 2023 (Spotlight)
Chenhongyi Yang*, Jiarui Xu*, Shalini De Mello, Elliot J. Crowley, Xiaolong Wang
Group Propagation Vision Transformer (GPViT) is a non-hierarchical vision transformer designed for general visual recognition with high-resolution features, whose core is the Group Propagation block that can exchange global information with a linear complexity.
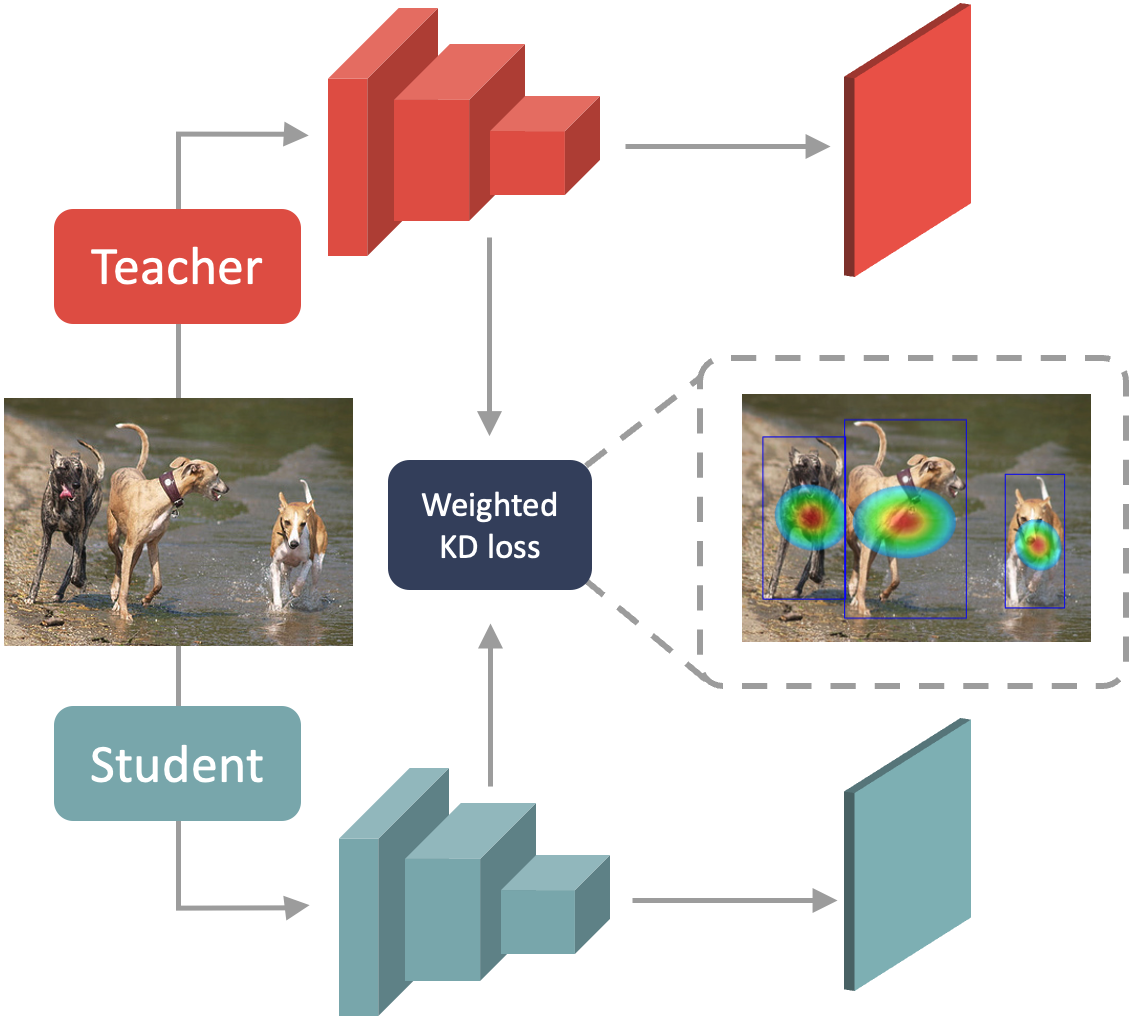
Prediction-Guided Distillation for Dense Object Detection
ECCV 2022
Chenhongyi Yang, Mateusz Ochal, Amos Storkey, Elliot J. Crowley
PGD is a high-performing knowledge distillation framework designed for single-stage object detectors. It distills every object in a few key predictive regions and uses an adaptive weighting scheme to compute the foreground feature imitation loss in those regions.
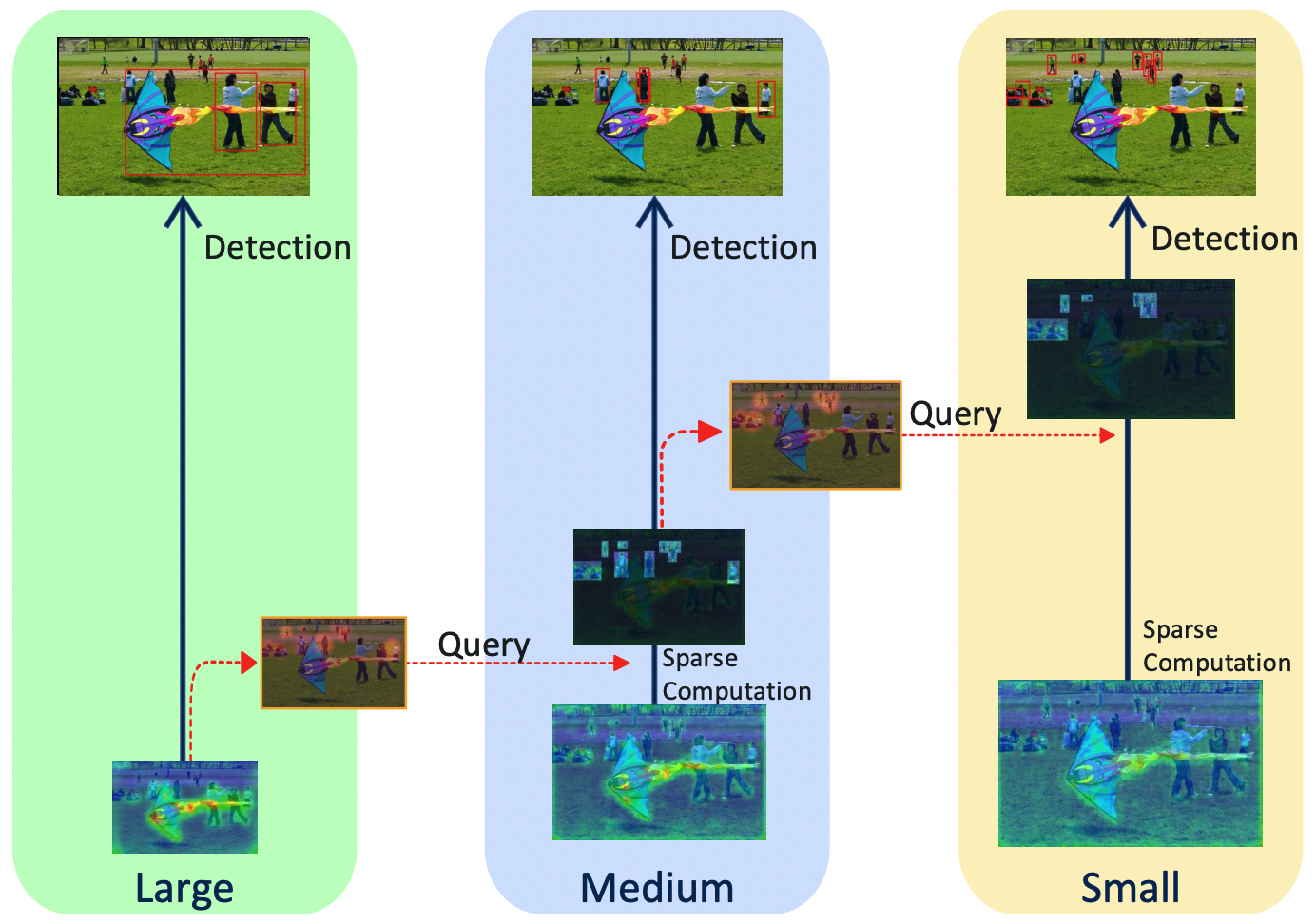
QueryDet: Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection
CVPR 2022 (Oral)
Chenhongyi Yang, Zehao Huang, Naiyan Wang
QueryDet achieves fast and accurate small object detection. Its core is the cascaded sparse query mechanism: rough locations of small objects are first found on low-resolution features, then those objects are accurately detected on high-resolution features using the efficient sparse convolution.
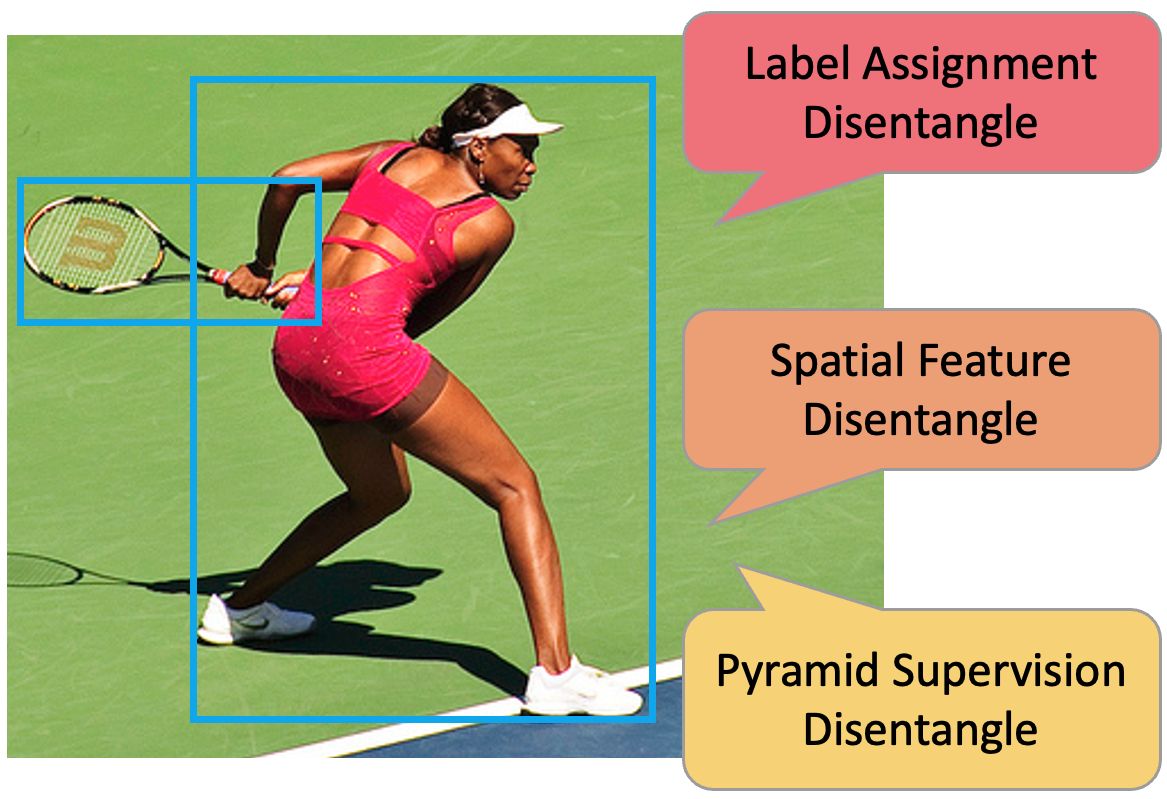
Disentangle Your Dense Object Detector
ACM Multimedia 2021 (Oral)
Zehui Chen*, Chenhongyi Yang*, Qiaofei Li, Feng Zhao, Zheng-Jun Zha, Feng Wu
We investigated the conjunction problem in the modern dense object detectors, based on which we proposed the Disentangled Dense Object Detector (DDOD) where three effective disentanglement mechanisms were designed for boosting dense object detectors' performance.
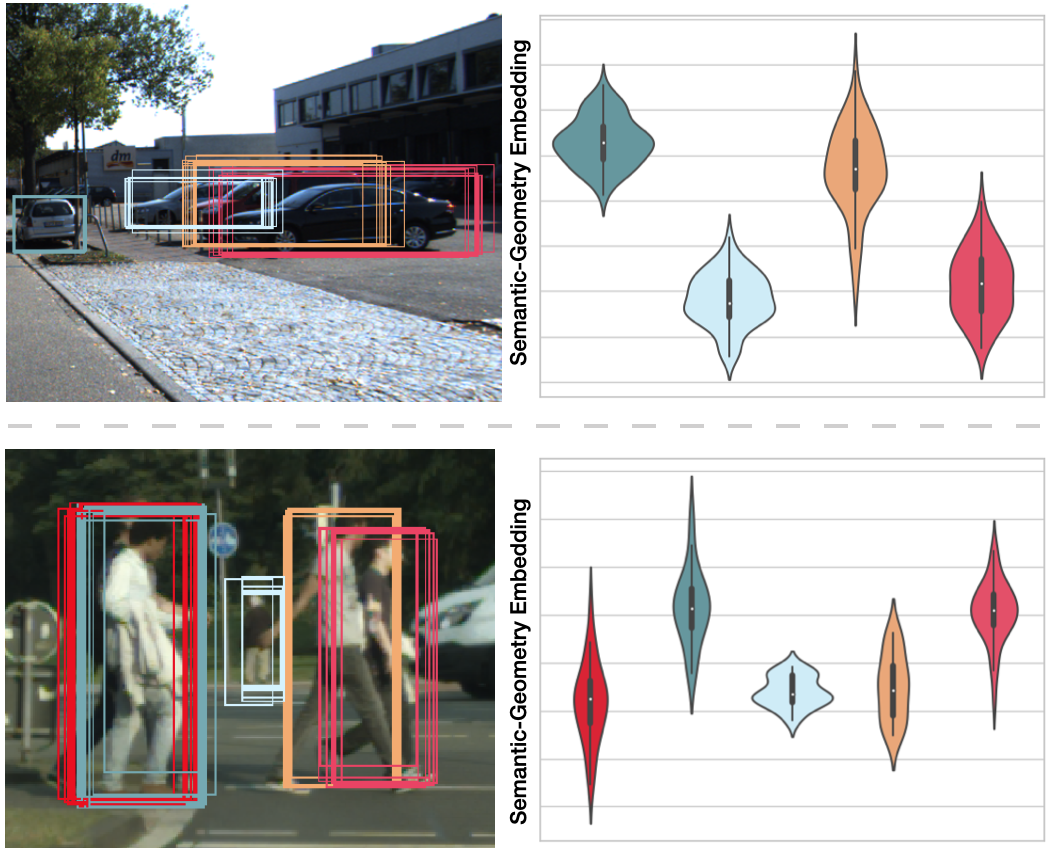
Learning to Separate: Detecting Heavily-Occluded Objects in Urban Scenes
ECCV 2020
Chenhongyi Yang, Vitaly Ablavsky, Kaihong Wang, Qi Feng, Margrit Betke
SG-NMS is a new non-maximum-suppression algorithm designed for detecting heavily-occluded objects. It is based on the semantic-geometry embedding mechanism where the embeddings of boxes belonging to the same object are pulled together and embeddings of boxes belong to different objects are pushed away. Then NMS is conducted based on the embedding distances.
Plug and Play Active Learning for Object Detection
CVPR 2024
Chenhongyi Yang, Lichao Huang, Elliot J. Crowley
PPAL is a plug-and-play active learning framework for object detection. It is based on two innotations: a novel object-level uncertainty re-weighting mechanism and a new similarity computing method for designed multi-instance images.
GPViT: A High Resolution Non-Hierarchical Vision Transformer with Group Propagation
ICLR 2023 (Spotlight)
Chenhongyi Yang*, Jiarui Xu*, Shalini De Mello, Elliot J. Crowley, Xiaolong Wang
Group Propagation Vision Transformer (GPViT) is a non-hierarchical vision transformer designed for general visual recognition with high-resolution features, whose core is the Group Propagation block that can exchange global information with a linear complexity.
Prediction-Guided Distillation for Dense Object Detection
ECCV 2022
Chenhongyi Yang, Mateusz Ochal, Amos Storkey, Elliot J. Crowley
PGD is a high-performing knowledge distillation framework designed for single-stage object detectors. It distills every object in a few key predictive regions and uses an adaptive weighting scheme to compute the foreground feature imitation loss in those regions.
QueryDet: Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection
CVPR 2022 (Oral)
Chenhongyi Yang, Zehao Huang, Naiyan Wang
QueryDet achieves fast and accurate small object detection. Its core is the cascaded sparse query mechanism: rough locations of small objects are first found on low-resolution features, then those objects are accurately detected on high-resolution features using the efficient sparse convolution.
Disentangle Your Dense Object Detector
ACM Multimedia 2021 (Oral)
Zehui Chen*, Chenhongyi Yang*, Qiaofei Li, Feng Zhao, Zheng-Jun Zha, Feng Wu
We investigated the conjunction problem in the modern dense object detectors, based on which we proposed the Disentangled Dense Object Detector (DDOD) where three effective disentanglement mechanisms were designed for boosting dense object detectors' performance.
Learning to Separate: Detecting Heavily-Occluded Objects in Urban Scenes
ECCV 2020
Chenhongyi Yang, Vitaly Ablavsky, Kaihong Wang, Qi Feng, Margrit Betke
SG-NMS is a new non-maximum-suppression algorithm designed for detecting heavily-occluded objects. It is based on the semantic-geometry embedding mechanism where the embeddings of boxes belonging to the same object are pulled together and embeddings of boxes belong to different objects are pushed away. Then NMS is conducted based on the embedding distances.
Latest update:
Thanks to Jack Turner for the website template.